Verileri ücretsiz parametreleri olmayan bir denkleme sığdırma
Öncelikle, sabit bir denkleminiz olduğunda "verilerimin denkleme ne kadar iyi uyduğunu görmenin" ne anlama geldiğini açıklayalım orijinal sorunuzdaki gibi. $ X $ ve $ y $ ile ilgili verileriniz var ve denkleminiz: $$ y = (3.5- (x / 10)) (x / 25) ^ {5/2} $$ ücretsiz parametrelere sahip değil. İşte bir olay örgüsü; veri noktaları dairelerdir, denklem katı bir eğridir:
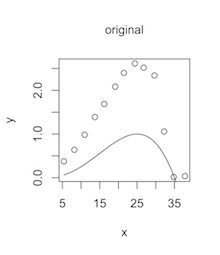
Dolayısıyla, orijinal sorunuzu yanıtlamak için verileriniz bu denkleme uymuyor çok iyi.
Bir denklemin parametrelerini verilerle eşleşecek şekilde uydurmak
İkinci olarak, "bir denklemi uydurmak" genellikle $ y $ ve $ x $ akılda tutulur, ancak formun ayrıntıları denklemin bazı bilinmeyen parametrelerine bağlıdır. Bu durumda "sığdırma", veriyle en iyi eşleşen parametrelerin değerlerini tahmin etmek için verilerin kullanılması anlamına gelir; örneğin eğri ile veriler arasındaki tutarsızlıkların karelerinin toplamını en aza indirerek. Yorumunuzdaki denklem biçiminde örtülü olan budur. (Görünüşe göre eksik olan bir parantezi $ z = 25 $ 'daki orijinal parametresiz denkleminizle eşleşecek şekilde düzelttim): $$ y = \ frac {35-x} {35-z} \ left (\ frac {x} { z} \ right) ^ {(z / 10)} $$ Şimdi "sığacak" bir şey var: verilerinize en yakın $ z $ değerini bulun. Bunu yapmak için en basit R işlevi nls 'dir. (Kullandığım R kodu cevabın sonundadır.) $ X $ ve $ y $ verilerinize en iyi uyan, ilk parametrenizle eşleşen 25 değeri değil, 33.1 $ z $ değeri tarafından sağlanır. -ücretsiz denklem. Yaklaşır, ancak gerçek değerlerin çoğunun büyük ölçüde altında olması da pek iyi değildir:
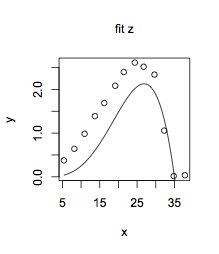
Görünüşe göre denklemin daha genel bir biçimi olabilir, örneğin: $$ y = \ frac {ax} {az} \ left (\ frac {x} {z} \ right) ^ {(z / b)} $$
$ z $, $ a $ ve $ b $, değerleri verilerden tahmin edilebilecek parametrelerdir. Bu daha genel biçimle, verilerinize oldukça yaklaşabilirsiniz: $ z = 34.0 $, $ a = 36.7 $ ve $ b = 17.8 $: 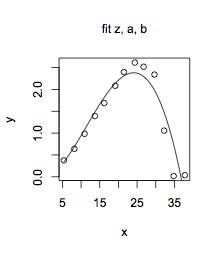
Denklemleri yerleştirmedeki tehlikeler
Üçüncüsü, bu uygun yola girerken çok dikkatli olmalısınız. John von Neumann'ın söylediği gibi, "Dört parametreyle bir fili sığdırabilirim ve beşiyle de hortumunu oynatmasını sağlayabilirim." Verilerle oynamaya başladığınızda aşırı uyum ciddi bir cazibedir.
Sizinki gibi bir durumda, parametrelerin gerçek dünyada ne anlama gelebileceğini düşünmeniz gerekir. Görünüşe göre, belirli bir sıcaklıkta ($ x $) büyüme oranında ($ y $) zirveye yol açan rekabet eden süreçler var ve eğer $ z $, $ a $ ve $ b $ parametreleri terimlerde belirli anlamlara sahipse Birbiriyle yarışan süreçler arasında bu tür bir uyumu yapmakta haklı olabilirsiniz. Diyelim ki, bu süreçlerin bir bakteri türünden diğerine nasıl farklılaştığı hakkında bir şeyler öğrenebilirsiniz. Ancak, bu tür parametreler (veya orijinal denkleminizdeki sabit değerler), belirli bir eğriye uyan daha önceki bazı veri kümelerini sağlamak için biri tarafından basitçe seçildiyse, o zaman büyük bir sorunla karşılaşırsınız.
Karşılaştırma uyumları farklı veri kümelerine
İki farklı veri kümesine uyan parametre değerlerini karşılaştırmak istiyorsanız, veri kümeleri arasında genel uyumların farklı olup olmadığını inceleyerek başlamak en iyisidir. Peter Dalgaard'ın R-help üzerine yakın tarihli bir yanıtında belirttiği gibi, bunu nls ile yapmanın "yararlı ve oldukça kolay gözden kaçan" bir yolu var. ( nls yardım sayfasının en altında bulunabilir.)
Farklı deneylerden $ x $ ve $ y $ değerlerinden oluşan ayrı vektörlerle çalışmak yerine, tüm verileri içeren havuzlanmış bir veri çerçevesi oluşturun. Her satır bir $ x $ değeri, ilişkili gözlemlenen $ y $ değeri ve spesifik denemeyi gösteren bir faktör değişkeni içermelidir. (Deneylerin sayı olarak değil faktör olarak kodlandığından emin olun.)
nls daha sonra farklı deneylere farklı parametre değerleri kümeleri sığdırmanıza olanak tanır. Çağrınızda Topt gibi genel parametreleri belirtmek yerine, parametreleri deneyle, örn. Topt [expt] , burada "expt" faktör ayırt edici deneylerin adıdır.
Bu nedenle, bir uyumu herkesle karşılaştırmak için anova 'yı kullanabilirsiniz. veriler, farklı deneyler için farklı parametre değerlerine izin veren bir uyuma karşı bireysel deneyleri yok sayarak. Bu uyumlar istatistiksel olarak ayırt edilebilir değilse, deneyler arasında ayrı ayrı uyan parametre değerlerinin farklılıklarına bakmamalısınız. Aşağıda R kodunu sunduğum bir örnek var.
Uyumlar farklıysa, o zaman uyan parametre değerlerini karşılaştırmayı düşünebilirsiniz. Çok büyük örneklem sınırında, uyan değerler normal dağılımlara sahip olmalıdır, ancak doğrusal olmayan uyumlar için "büyük" ün ne anlama geldiği açık değildir ve denkleme bağlı olarak anlam değişebilir. Bu nedenle p değerlerinin geçerliliği ile ilgili sorular olacaktır.
Normalliği varsaymak istiyorsanız, nls , bu varsayım altında p -değerlerini elde etmek için kullanabileceğiniz parametre değerleri için standart hataları bildirir. Bir z testi kabaca bir genel bakış sağlayabilir, ancak muhtemelen Welch'in t -testi yaklaşımını kullanmak daha iyi olacaktır. farklı standart hatalar ve iki parametre tahmini arasındaki serbestlik dereceleri. Bu yaklaşımı uygulamak için, Welch'in testi formülündeki $ \ frac {s_i ^ 2} {N_i} $ gibi terimlerin nls çıktısındaki $ SE_i ^ 2 $ ile eşdeğer olduğuna dikkat edin.
R kodu
R kodu açısından, sıcaklık-tepki eğriniz için genel bir fonksiyon tanımlamak en basitiydi:
trcFunc <- function (x, z, a, b) {((ax) / (az)) * ((x / z) ^ (z / b))}
ardından verilerinizi eğri ile karşılaştırmak için orijinal denkleminizle eşleşen parametreler için belirli değerler verin:
plot (x, y) curve (trcFunc (x, 25,35,10), add = TRUE)
Uydurma için nls işlevini kullandım, örneğin tek başına $ z $
Zfit < - nls (y ~ trcFunc (x, z, 35,10), start = list (z = 30))
veya 3 parametre değerinin tümü için
ZABfit <- nls (y ~ trcFunc (x, z, a, b), start = list (z = 30, a = 35, b = 10))
ZABfit Doğrusal Olmayan regresyon modeli modeli: y ~ trcFunc (x, z, a, b) ile uydurulmuş parametre değerleri data: parent.frame () zab 33.98 36.74 17.84 artık kareler toplamı: 1.228 Yakınsamaya kadar yineleme sayısı: 5 Elde edilen yakınsama toleransı: 1.35e-06
ve verileri ve eğriyi karşılaştırın :
plot (x, y, main = "fit z, a, b") eğri (trcFunc (x, 33.98,36.74,17.84), add = TRUE)
Yeni ilişki biçimi; uyumları karşılaştırma OP'de yapılan bir düzenlemede $ y $ ile $ x $ arasındaki ilişkinin yeni genel biçimi ile, uydurma için yeni bir genel işlev şu şekilde tanımlanır:
newFunc <- function (x, Topt, Tmax, Ymax) {Ymax * ((Tmax-x) / (Tmax-Topt)) * (x / Topt) ^ (Topt / (Tmax-Topt) )}
İki deneyi karşılaştırmak için, sorunun başında veri olarak expt1 ve ikinci veri kümesi olarak expt2 alın (x2, y2) sonuna doğru ve yukarıda önerildiği gibi havuzlanmış bir veri çerçevesi oluşturun. Daha sonra deneyler arasındaki farkları göz ardı ederek uygunluk şudur:
fitPool <- nls (y ~ newFunc (x, Topt, Tmax, Ymax), data = newDF, start = list (Topt = 25, Tmax = 35, Ymax = 2.5))
ve iki deney için ayrı parametre değerlerine izin verme şudur:
fitSeparate <- nls (y ~ newFunc (x, Topt [expt], Tmax [expt], Ymax [expt]), data = newDF, start = list (Topt = c (25,25), Tmax = c (35,35), Ymax = c (2,5 , 2.5)))
Havuzlanmış ve ayrı uyumlar önemli ölçüde farklı değildir:
> anova (fitPool, fitSeparate) Varyans TableModel'in Analizi 1: y ~ newFunc (x, Topt, Tmax, Ymax) Model 2: y ~ newFunc (x, Topt [expt], Tmax [expt], Ymax [expt]) Res.Df Res.Sum Sq Df Sum Sq F değeri Pr (>F) 1 19 1.9215 2 16 1.4410 3 0.48046 1.7782 0.1918
Başlangıç değerleri seçiminde uyarı
Not Doğrusal olmayan eğri uydurmada olabileceği gibi, "en iyi" uyum, parametre değerleri için ilk tahmin olarak sağladığınız şeye bağlı olabilir. Verilerinizle, $ z $ için 26 ilk tahmin ve $ a $ ve $ b $ için 35 ve 10 sabit değerler sağlasaydım:
Zfit26start <- nls (y ~ trcFunc (x, z, 35,10), start = list (z = 26))
$ z $ için döndürülen değer 13.1'dir ve bu hiç uymuyor:
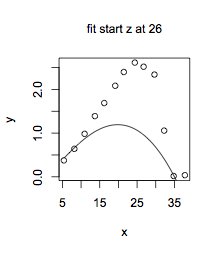
Bunun nedeni, programın tüm $ z $ değerleri aralığını değerlendirecek şekilde ayarlanmaması ve $ z = 26 $ 'dan aramaya başladığında "yerel optimum" olarak adlandırılan durumda kalmasıdır. $ Z $ başlangıç değerlerini 20'den 25'e kadar denediğimde nls programı bir hata verdi:
numericDeriv'de hata (form [[3L]], isimler (ind), env): Model değerlendirilirken eksik değer veya sonsuzluk üretildi
19 veya daha düşük başlangıç değerleri z $ z $ için 13.1 gibi çok uygun olmayan bir tahmin verdi. Doğrusal olmayan bir eğri uydurma ile çok fazla keşif yapmadan "küresel" optimumun elde edileceğine güvenemezsiniz.